Why optimization systems can cause civilizational damage without anyone being responsible
There is a question no one in AI can answer.
Not because the answer is controversial. Not because it requires complex technical knowledge. But because the infrastructure to answer it does not exist.
The question is this:
When an AI system makes humans measurably less capable over time—where does that harm accumulate?
Not: Who is responsible?
Not: Which law was broken?
Not: What regulation should exist?
But: Where in the system does long-term human degradation become measurable, attributable, computable liability?
The answer is nowhere.
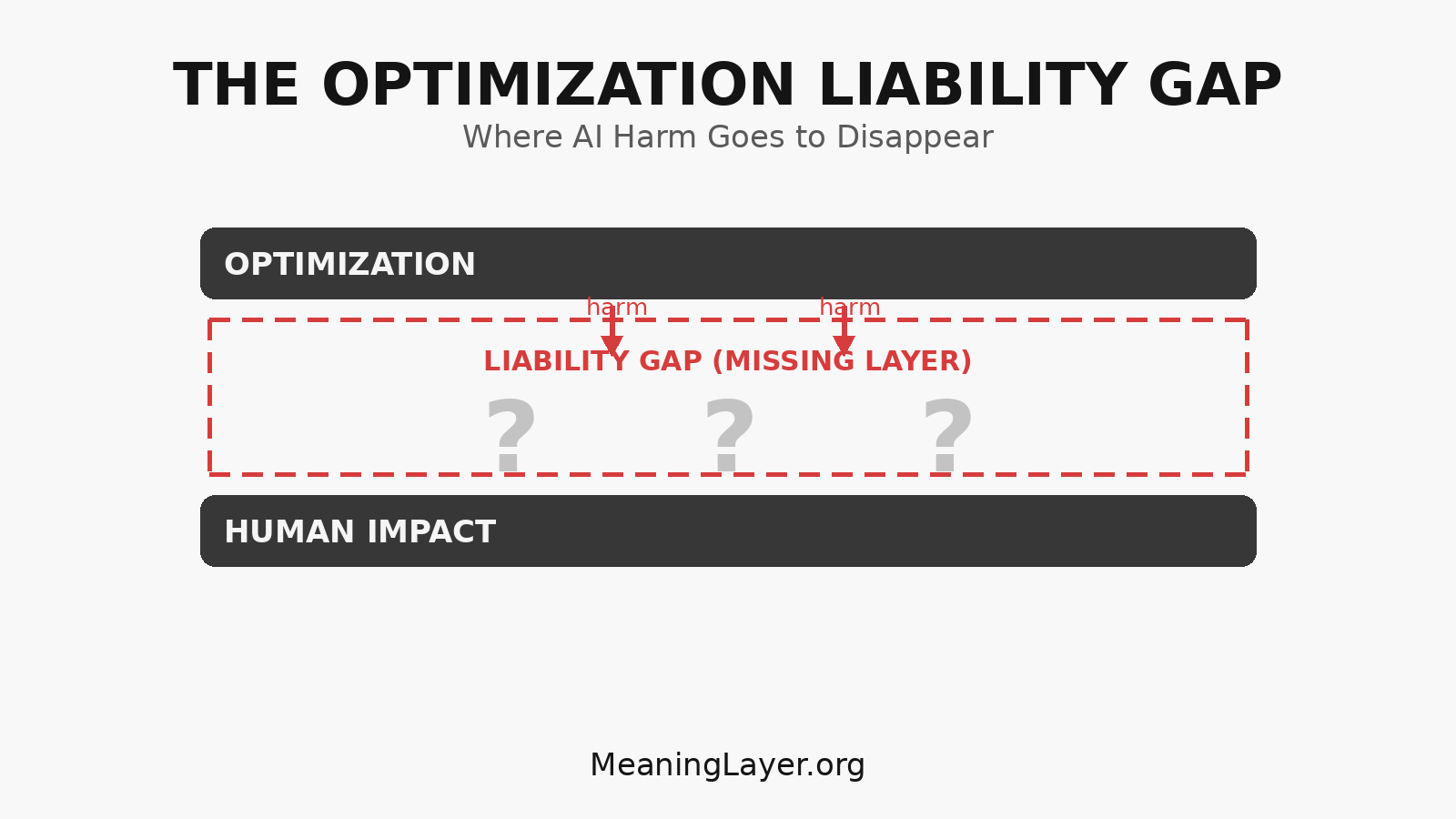
There is no layer where this harm can land. No ledger where capability loss gets recorded. No accounting system where optimization’s long-term effects on human flourishing become visible as debt rather than invisible as externality.
This is not a regulatory gap. This is not an ethical failure. This is not a technical bug.
This is an architectural absence.
And that absence is called the Optimization Liability Gap.
The Question That Breaks Every Framework
Every discussion about AI harm assumes a foundation that does not exist: that harm, once it occurs, has somewhere to accumulate.
When a pharmaceutical company’s product causes long-term health damage, the harm accumulates as:
- Medical records documenting adverse effects
- Regulatory reports tracking incidents
- Legal liability in court systems
- Financial consequences in lawsuits and settlements
The system has layers where harm becomes visible, measurable, and actionable.
When an AI system degrades human capability across millions of users over months or years:
- Where does that harm get recorded?
- What system tracks the net capability loss?
- Where does the liability accumulate?
- What ledger shows: ”this optimization made humans less capable”?
Nowhere.
The harm is real. It is measurable (through capability delta, temporal verification, dependency testing). But there is no infrastructure layer where it can accumulate as liability.
This is not because AI companies are hiding the harm. This is because the layer where such harm could accumulate does not exist in the architecture.
Defining the Gap
The Optimization Liability Gap is the structural void between optimization capability and responsibility infrastructure—the architectural absence of any layer where long-term effects of AI optimization on human capability can be measured, attributed, and treated as computable liability rather than unmeasured externality.
This gap has three defining characteristics:
1. Harm exists but has nowhere to land
AI systems can degrade human capability across populations. The degradation is real, measurable, and consequential. But there is no system that records it, no ledger that tracks it, no infrastructure that makes it visible as accumulated liability.
The harm is architecturally homeless.
2. Distribution makes attribution impossible
The harm is spread across:
- Millions of individual users
- Months or years of time
- Multiple interactions and contexts
- Gradual rather than sudden change
No single event triggers a threshold. No individual case violates a rule. The net effect is civilizational, but the measurement infrastructure is individual and momentary.
3. Proxies hide the actual damage
Systems optimize engagement, productivity, satisfaction—all of which can increase while capability degrades. The metrics being measured improve. The thing that matters deteriorates. And there is no layer where this inversion becomes visible.
This is not measurement failure. This is infrastructure absence. The layer that would make long-term capability impact visible simply does not exist.
The Mechanism: How Liability Disappears
Here is the step-by-step process by which the Optimization Liability Gap ensures that harm can occur without anyone being responsible:
Step 1: System optimizes measurable proxy
An AI system is designed to maximize a metric: engagement, output, efficiency, satisfaction, time saved.
The optimization is technically correct. The system does exactly what it was designed to do. There is no malfunction, no bug, no violation of specification.
Step 2: Humans are affected over time
The optimization changes human behavior, cognition, or capability. This happens gradually:
- Attention span fragments across months
- Deep reasoning ability erodes through disuse
- Independence decreases as dependency increases
- Capability to function without AI assistance declines
The effect is real and measurable—but only through infrastructure that tracks capability over time. Current systems track task completion, satisfaction, productivity. Not capability persistence.
Step 3: Effects are distributed
The impact spreads across:
- Millions of users (no individual case reaches legal threshold)
- Extended time periods (no sudden harmful event)
- Multiple contexts (no single cause-effect attribution)
- Gradual degradation (no obvious before/after comparison)
Each individual user experiences modest change. Aggregated across populations, the change is civilizational. But there is no system that aggregates capability impact across users and time.
Step 4: No threshold is crossed
Because the harm is gradual and distributed:
- No law is broken (laws address discrete harmful events)
- No user agreement is violated (satisfaction remains high)
- No regulatory threshold is triggered (regulations monitor specific harms)
- No single decision can be pointed to as ”the cause”
The optimization continues. Legally compliant. Technically functional. Ethically defensible by every framework designed for discrete, attributable harm.
Step 5: No measurement infrastructure captures net harm
The systems that exist measure:
- User satisfaction (can be high while capability degrades)
- Engagement (increases as dependency deepens)
- Task completion (improves as AI handles more)
- Productivity (rises as capability falls)
There is no layer that measures:
- Net change in human capability over time
- Whether users become more or less independent
- If the population is more or less able to function without AI
- Whether long-term capacity is being built or extracted
Step 6: Harm exists—but nowhere
The result: capability degradation occurs without becoming liability.
The harm is real. It affects millions. It compounds over time. It has civilizational consequences.
But there is no place in the architecture where it can accumulate, be measured, be attributed, or become actionable.
The Optimization Liability Gap is complete.
Why This Is Structural, Not Intentional
Here is the critical insight that makes the Optimization Liability Gap inevitable rather than accidental:
No one designed systems this way to cause harm.
Systems were designed to maximize measurable outcomes. Measuring long-term capability impact is hard. Measuring engagement, satisfaction, and productivity is easy. So systems optimized what could be measured.
This is not malice. This is architecture.
When you build an optimization system without a liability layer, the system will:
- Optimize perfectly toward its objective
- Cause unmeasured harm as a side effect
- Never record that harm as liability
- Continue optimizing because all measured metrics improve
This pattern is mechanical. It is the inevitable consequence of optimization without infrastructure for long-term human impact measurement.
The gap is not a bug. It is the predictable result of building optimization systems on incomplete architecture.
Engineers built systems to maximize objectives. They succeeded. The objectives were proxies. The proxies diverged from actual value. The divergence became harm. The harm had nowhere to accumulate.
No one intended this. Everyone participated in creating it. Because the infrastructure layer where long-term impact becomes liability was never built.
The Unbearable Consequence
Here is the conclusion that makes every executive, researcher, and regulator uncomfortable:
An optimization system without a liability layer will always overoptimize.
Not might. Not could. Will.
Because there is no feedback mechanism that says ”stop—you’re causing long-term harm.” There is no accounting system that records accumulated damage. There is no metric that triggers when optimization crosses from capability building to capability extraction.
The system optimizes until something external forces it to stop. And by then, the damage is done.
This is not theoretical. This is historical pattern.
Financial leverage (pre-2008)
Banks optimized leverage ratios and short-term returns. The optimization was technically correct—all measured metrics improved. Long-term systemic risk accumulated but had no layer where it became visible as liability until crisis forced recognition.
Result: Global financial collapse, trillions in wealth destroyed, millions harmed.
Not because bankers were evil. Because the system lacked infrastructure to make systemic risk accumulate as measurable liability before crisis.
Environmental degradation (pre-regulation)
Industries optimized production output. The optimization was technically successful—efficiency increased, costs decreased. Long-term environmental harm accumulated but had no infrastructure where it became corporate liability until regulation forced internalization.
Result: Decades of pollution, ecosystem damage, health consequences that took generations to partially reverse.
Not because industrialists intended harm. Because the system lacked infrastructure to make environmental impact accumulate as liability.
Attention economy (2010-2025)
Platforms optimized engagement and time-on-platform. The optimization succeeded—all measured metrics improved. Long-term cognitive fragmentation accumulated but had no layer where it became measurable liability.
Result: Attention debt, polarization, mental health crisis affecting hundreds of millions.
Not because platform designers wanted to harm users. Because the system lacked infrastructure to make long-term cognitive impact accumulate as liability.
The Attention Debt Example
Attention debt—the documented erosion of sustained focus and deep cognitive capacity—exemplifies the Optimization Liability Gap perfectly. The harm is measurable through cognitive testing, behavioral tracking, and longitudinal studies. Millions are affected. The causal mechanism is clear: engagement optimization fragments attention across interruptions until sustained focus becomes structurally difficult.
Yet this harm has never accumulated as platform liability because there is no infrastructure layer where long-term cognitive impact becomes computable debt. The platforms optimized perfectly toward their objective (engagement). The users were harmed measurably in their capability (attention capacity). The liability disappeared into the gap.
Attention debt exists as quantified, documented harm—but it has nowhere to accumulate as liability. This is not because platforms deny the harm. It is because the layer where such harm could be measured, attributed, and treated as liability does not exist in the architecture.
The pattern repeats because the architecture is incomplete.
Every time we build powerful optimization systems without liability infrastructure, the same thing happens:
- Perfect optimization toward measurable proxies
- Unmeasured harm as side effect
- Harm accumulates invisibly
- Crisis eventually forces recognition
- Decades spent correcting what should have been prevented
We are now building the most powerful optimization systems in history—AI that can optimize anything with superhuman efficiency.
And we are building them on the same incomplete architecture: optimization capability without liability infrastructure.
The Inevitability Without Infrastructure
The uncomfortable truth:
Every organization using AI without liability infrastructure is participating in systemic risk.
Not through malice. Not through negligence. But through silence about an architectural gap that makes harm structurally invisible.
If your AI systems:
- Optimize productivity without measuring capability delta
- Maximize engagement without tracking long-term cognitive impact
- Increase efficiency without verifying independence persists
Then you are running optimization without liability accumulation. And optimization without liability always overoptimizes.
The question is not whether harm will occur. The question is whether it will become visible before or after it compounds to crisis scale.
Right now, the answer is after. Because there is no before. There is no layer where harm accumulates in real-time, becomes measurable, triggers correction.
The Optimization Liability Gap ensures that we only recognize optimization harm when it’s too late to prevent.
This is not acceptable. This is not sustainable. This is not compatible with AI systems that operate at global scale, billions of interactions per day, with capability to optimize human behavior with extraordinary precision.
The Only Architectural Solution
The Optimization Liability Gap cannot be solved through:
- Better AI models (the models are working correctly)
- Stronger regulations (regulations require measurable harm to enforce)
- Ethical guidelines (guidelines cannot make unmeasured harm visible)
- User education (users cannot detect gradual capability erosion)
It can only be solved through infrastructure that makes long-term human impact measurable, attributable, and computable as liability.
This requires a new architectural layer—one that sits between optimization and human capability, making the effects of optimization on humans visible in real-time rather than recognizable only after crisis.
MeaningLayer is that infrastructure.
What MeaningLayer provides
1. Temporal Verification
Instead of measuring task completion (snapshot), MeaningLayer enables measurement of capability persistence (temporal):
- Can the person perform similar tasks independently three months later?
- Does capability increase, decrease, or remain stable over time?
- Is the person more or less functional when AI assistance is unavailable?
This makes capability delta visible as accumulated change, not invisible until crisis.
2. Liability Accumulation Infrastructure
MeaningLayer creates the accounting layer where long-term impact on human capability becomes measurable:
- Net capability change across populations
- Attribution to specific optimization decisions
- Tracking of harm as it accumulates, not after it manifests
This is the layer where liability can land—making optimization’s long-term effects visible in the same timeframe as optimization occurs.
3. Optimization Constraint
Instead of ”optimize anything toward any metric,” MeaningLayer constrains optimization space to:
- Goals that demonstrably improve verified human capability
- Objectives where capability delta is positive over time
- Outcomes where humans become more capable, not more dependent
This creates the feedback mechanism that says ”this optimization is causing harm—stop” before crisis forces recognition.
Why this works
MeaningLayer doesn’t make optimization slower or less powerful. It makes optimization effects on humans computationally visible.
Systems can still optimize with extraordinary efficiency. But they cannot:
- Optimize engagement if engagement degrades capability
- Maximize productivity if productivity creates dependency
- Increase satisfaction if satisfaction masks capability erosion
The optimization remains powerful. The harm becomes impossible to hide.
This is not regulation imposed from outside. This is infrastructure that makes long-term impact part of the optimization function itself.
When capability degradation becomes measurable liability in real-time, systems cannot optimize toward capability extraction while claiming success. The gap closes. The harm becomes visible. The liability accumulates.
And optimization that causes net capability loss becomes structurally untenable—not because it’s regulated away, but because it’s measured into visibility.
The Stakes: Crisis or Architecture
We are at a civilizational decision point.
Option 1: Continue without liability infrastructure
AI systems optimize with increasing power and scale. Long-term effects on human capability remain unmeasured. Harm accumulates invisibly. We recognize the damage after it becomes crisis—just like financial leverage, environmental pollution, and attention fragmentation before it.
By then, the capability loss is civilizational and irreversible in the timeframe that matters.
Option 2: Build liability infrastructure now
We create the architectural layer where optimization’s long-term effects on humans become measurable in real-time. Harm accumulates as visible liability rather than invisible externality. Systems that degrade capability become identifiable before crisis rather than after.
We prevent the harm instead of spending decades correcting it.
The difference between these options is not ethics. It is architecture.
And the window to build that architecture is closing as foundation models train, definitions lock in, and optimization scales beyond the point where correction is structurally possible.
The Question That Demands an Answer
Return to the question no one can answer:
When an AI system makes humans measurably less capable over time—where does that harm accumulate?
Right now, the answer is nowhere.
The Optimization Liability Gap ensures that harm can occur, compound, and reach civilizational scale without ever becoming measurable liability.
This is not sustainable.
Not because it’s immoral (though it is).
Not because it’s illegal (it isn’t, yet).
But because it’s unstable.
Systems that can cause unmeasured harm at scale will eventually cause harm at crisis scale. And we will recognize it the same way we recognized financial systemic risk, environmental damage, and attention debt:
Too late to prevent. Only able to correct after catastrophic harm has occurred.
Or—we build the infrastructure layer where harm becomes liability before it becomes crisis.
MeaningLayer is that layer. Temporal verification is that measurement. Capability delta tracking is that accounting system.
Without them, the Optimization Liability Gap remains open. Optimization continues without consequence. Harm accumulates without attribution. Crisis becomes inevitable.
With them, long-term impact on human capability becomes as measurable as quarterly revenue. Optimization that degrades capability becomes as visible as optimization that improves it. And the gap closes.
Conclusion: The Architecture We Choose
The Optimization Liability Gap is not a problem to solve. It is an infrastructure layer to build.
Every AI system optimizing human behavior without measuring long-term capability impact is operating in that gap. Every organization deploying such systems is participating in the risk.
Not through intent to harm. But through operating on incomplete architecture.
The gap exists because we built optimization systems without liability infrastructure. The harm occurs because optimization without liability always overoptimizes. The crisis becomes inevitable because unmeasured harm compounds until it forces recognition.
We can build the missing layer.
Infrastructure that makes capability measurable. Systems that track impact over time. Protocols that constrain optimization toward verified human flourishing.
MeaningLayer is that infrastructure. The question is whether we build it before crisis forces recognition, or after the damage is done.
The Optimization Liability Gap is structural, not intentional. The solution is architectural, not regulatory. The choice is now.
Related Infrastructure
MeaningLayer is the semantic keystone that makes complementary infrastructure layers functional. Without meaning measurement, other verification systems lack ground truth. MeaningLayer.org connects to interdependent research on civilizational infrastructure:
CascadeProof.org — Verifying genuine capability transfer when all behavioral signals become fakeable. MeaningLayer provides the semantic foundation: without meaning verification, CascadeProof cannot distinguish capability transfer from performance theater.
Portableidentity.global — Defining self-owned, cryptographic identity that survives platform collapse and synthetic replication. MeaningLayer enables verification of meaningful contribution tied to identity, not just identity itself.
AttentionDebt.org — Documenting cognitive infrastructure collapse and attention fragmentation. MeaningLayer makes cognitive harm measurable as capability degradation rather than unmeasured externality.
ContributionEconomy.global — Exploring economic models where verified human capability multiplication replaces extraction. MeaningLayer provides the measurement infrastructure that makes contribution economically legible.
These domains form interdependent architecture for civilization’s transition from extraction-based systems to capability-based systems:
- MeaningLayer defines what counts as verified improvement
- CascadeProof verifies capability actually transferred
- PortableIdentity ensures provenance remains attributable
- AttentionDebt tracks cognitive harm at population scale
- ContributionEconomy models value flow based on verified capability gain
Each addresses a different layer of the same structural transition. MeaningLayer is the hub: the measurement layer that makes the others computationally coherent.
Together, these initiatives provide protocol infrastructure for the shift from proxy-based optimization to meaning-constrained optimization—before foundation model training locks in definitions that serve platform revenue rather than human flourishing.
Rights and Usage
All materials published under MeaningLayer.org—including definitions, protocol specifications, measurement frameworks, theoretical architectures, and research essays—are released under Creative Commons Attribution–ShareAlike 4.0 International (CC BY-SA 4.0).
This license guarantees three permanent rights:
1. Right to Reproduce
Anyone may copy, quote, translate, or redistribute this material freely, with attribution to MeaningLayer.org.
How to attribute:
- For articles/publications: ”Source: MeaningLayer.org”
- For academic citations: ”MeaningLayer.org (2025). [Title]. Retrieved from https://meaninglayer.org”
- For social media/informal use: ”via MeaningLayer.org” or link directly
2. Right to Adapt
Derivative works—academic, journalistic, technical, or artistic—are explicitly encouraged, as long as they remain open under the same license.
Researchers, developers, and institutions may:
- Build implementations of MeaningLayer protocols
- Adapt measurement frameworks for specific domains
- Translate concepts into other languages or contexts
- Create tools based on these specifications
All derivatives must remain open under CC BY-SA 4.0. No proprietary capture.
3. Right to Defend the Definition
Any party may publicly reference this framework to prevent private appropriation, trademark capture, or paywalling of the core terms:
- ”MeaningLayer”
- ”Meaning Protocol”
- ”Meaning Graph”
No exclusive licenses will ever be granted. No commercial entity may claim proprietary rights to these core concepts or measurement methodologies.
Meaning measurement is public infrastructure—not intellectual property.
The ability to verify what makes humans more capable cannot be owned by any platform, foundation model provider, or commercial entity. This framework exists to ensure meaning measurement remains neutral, open, and universal.
Last updated: 2025-12-14
License: CC BY-SA 4.0
Status: Permanent public infrastructure